I finally got a GPU capable of dynamic parallelism, so I finally decided to mess around with CUDA 5. But I discovered a couple of configuration options that are required if you want to enable dynamic parallelism. You'll know you haven't configured things correctly if you attempt to call a kernel from the device and you get the following error message:
ptxas : fatal error : Unresolved extern function 'cudaGetParameterBuffer'
Note: this assume you have already selected the appropriate CUDA 5 build customizations for your project
Open the project project properties 1. Make sure to set "Generate Relocatable Device Code" to "Yes (-rdc=true)" 2. Set "code generation" to "compute_35,sm_3″
2. Set "code generation" to "compute_35,sm_3″ 3. Finally add "cudadevrt.lib" to the CUDA Linker's "Additional Dependencies"
3. Finally add "cudadevrt.lib" to the CUDA Linker's "Additional Dependencies"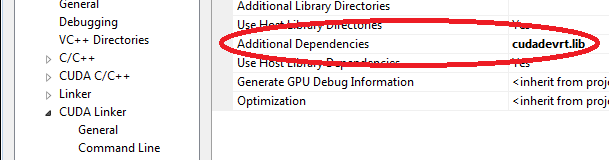
Citation
@online{rauwendaal2013,
author = {Randall Rauwendaal},
title = {CUDA 5: {Enabling} {Dynamic~Parallelism}},
date = {2013-03-23},
url = {https://raegnar.github.io/rauwendaal.net//posts/2013_03_23 - CUDA 5 Enabling Dynamic Parallelism},
langid = {en}
}